Versione Mobile | Vai alla versione Desktop
Differenze tra versione Mobile e versione Desktop
OBIETTIVI:
![]() apprendere il concetto di «limiti fiduciali»
apprendere il concetto di «limiti fiduciali»
![]() utilizzare l'errore standard per il calcolo dei limiti fiduciali
utilizzare l'errore standard per il calcolo dei limiti fiduciali
Proseguiamo l'esempio lasciato in sospeso nella ![]() Unità precedente (se non l'hai letta, ti consiglio di farlo ora). Riassumendo: avevi studiato un campione di 40 suini, avevi calcolato un semplice valore statistico: la proporzione di animali positivi per una certa malattia. I suini positivi erano 14, quindi la proporzione era risultata pari a 14/40=0.35 (35%); l'errore standard di questa proporzione era di 0.0754 (7.54%).
Unità precedente (se non l'hai letta, ti consiglio di farlo ora). Riassumendo: avevi studiato un campione di 40 suini, avevi calcolato un semplice valore statistico: la proporzione di animali positivi per una certa malattia. I suini positivi erano 14, quindi la proporzione era risultata pari a 14/40=0.35 (35%); l'errore standard di questa proporzione era di 0.0754 (7.54%).
L'errore standard rappresenta un indice della variabilità della proporzione; possiamo anche dire è una misura l'affidabilità della proporzione: più esso è piccolo, più la proporzione che hai calcolato nel campione si avvicina alla vera proporzione della popolazione. Quanto più piccolo è l'errore standard, tanto più attendibile è il valore statistico che hai calcolato.
Nella pratica, l'errore standard serve per calcolare l'intervallo fiduciale o intervallo di confidenza (sinonimo: limiti fiduciali) della proporzione. L'intervallo di confidenza è l'intervallo di valori entro i quali si stima che cada, con un livello di probabilità scelto a piacere, il valore vero della popolazione. In realtà si sceglie quasi sempre un livello di probabilità di 0.95 o, più raramente, 0.99, ottenendo rispettivamente l'intervallo di confidenza al 95% o al 99%.
L'intervallo di confidenza per una proporzione si calcola come segue:

Certamente ti chiederai da dove vengono i valori scritti in blu nello schema soprastante. Per quanto riguarda i moltiplicatori dell'errore standard, la risposta presuppone nonzioni di statistica un po' avanzate; quindi sarebbe troppo complicata ed al di fuori dello scopo di questo Quaderno. Quindi ti consiglio di prendere questi due valori (1.96 e 2.58) come «numeri magici» da utilizzare senza porti troppe domande.
L'intervallo di confidenza calcolato come: valore statistico ± 1 volta l'errore standard fornisce una «confidenza» del 68% circa, troppo bassa per essere di una qualche utilità pratica.
Per quanto riguarda i due livelli (0.95 e 0.99, oppure in percentuale 95% e 99%) di probabilità, si può dire che essi sono adottati per convenzione, e rappresentano uno standard nel campo bio-medico. Essi consentono di avere una probabilità abbastanza alta (appunto 95% o 99%) di individuare l'intervallo «giusto» senza però ampliarlo eccessivamente. Infatti è evidente, dalle formule dello schema soprastante, che l'ampiezza dell'intervallo cresce con l'aumentare della probabilità.
Torniamo al nostro esempio. Con i dati che hai a disposizione, l'intervallo di confidenza 95% si calcola come segue:
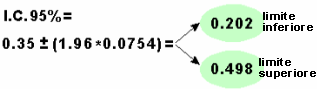
Ed analogamente l'intervallo di confidenza 99%:
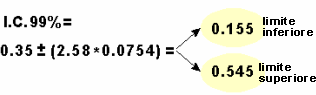
In conclusione, puoi affermare:
Ripetiamo ancora il significato dell'espressione «confidenza 95%»: c'è una probabilità del 95% che l'intervallo trovato includa la vera caratteristica della popolazione.
Questa definizione non è del tutto corretta, e certamente uno statistico «puro» potrebbe storcere il naso... ma in questa sede è giustificata dal «Teorema di Saki» che recita: una piccola inesattezza a volte risparmia tonnellate di spiegazioni :-))
Ecco una definizione migliore (ma anche un po' più difficile da assimilare): «confidenza 95%» significa che se ripetessimo la stessa indagine per 100 volte con gli stessi metodi (ma su 100 campioni diversi), probabilmente otterremmo ogni volta una stima diversa; tuttavia, il vero valore della popolazione sarebbe all'interno del nostro intervallo di confidenza 95 volte su 100. In altre parole, l'intervallo di confidenza fornisce un risultato aderente alla realtà nel 95% dei casi.
Prima di trattare questo argomento, vale la pena di fare un po' di chiarezza riguardo a due statistiche sulle quali molto spesso c'è confusione: la deviazione standard e l'errore standard.
La ![]() deviazione standard indica variabilità di una misura effettuata sul campione; invece, l'errore standard indica la variabilità di un valore statistico (es. una percentuale, una media ecc.). Devi fare attenzione a non confondere l'errore standard con la deviazione standard! Si tratta di due cose molto diverse. Ripetiamo di nuovo:
deviazione standard indica variabilità di una misura effettuata sul campione; invece, l'errore standard indica la variabilità di un valore statistico (es. una percentuale, una media ecc.). Devi fare attenzione a non confondere l'errore standard con la deviazione standard! Si tratta di due cose molto diverse. Ripetiamo di nuovo:
ESEMPIO. Sono stati pesati singolarmente 100 suini, ottenendo alttrettanti valori (es. 94.0, 92.2., 97.9 ecc.). Il peso medio è risultato pari a 95.2 kg. Sui 100 valori del peso di ciascun suino puoi calcolare la deviazione standard (come già descritto ![]() altrove). Sulla media ottenuta puoi invece calcolare l'errore standard.
altrove). Sulla media ottenuta puoi invece calcolare l'errore standard.
Abbiamo visto come si calcola l'errore standard di una proporzione (o percentuale). Ma come si fa a calcolare l'errore standard di una media? È molto semplice: basta dividere la deviazione standard per la radice quadrata della numerosità del campione (n):

Nota che, ancora una volta, l'errore standard dipende dalla numerosità del campione: più grande è il campione, più piccolo sarà l'errore standard, e quindi più attendibilità la media calcolata.
L'errore standard della media può essere utilizzato per calcolare l'intervallo di confidenza, così come già visto per le proporzioni. Il calcolo è molto simile:

dove t è un coefficiente desumibile dalla «Tabella dei valori t per la distribuzione di Student» (ne trovi qui una semplificata). Nell'uso della tabella, devi tener conto che i gradi di libertà si calcolano come: numerosità del campione - 1.
.ESEMPIO. Hai misurato il peso di un campione di 29 suini di un gruppo in allevamento. La media è risultata pari a 82.5 kg, con una deviazione standard di 3.50 kg. L'errore standard della media è:
![]()
L'intervallo di confidenza 95%, con 28 gradi di libertà, è:
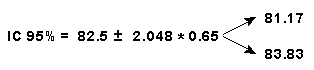
Puoi concludere, con confidenza 95%, che il peso medio dei suini del gruppo è compreso fra 81.17 e 83.83kg.
NELLA PROSSIMA UNITÀ:
si prende in considerazione l'importanza della dimensione del campione ai fini di ottenere una stima sufficientemente precisa; si parla anche dei fattori che occorre tenere presente per determinare la numerosità del campione.
![]()