OBIETTIVO:
![]() disegnare uno schema logico che permetta di valutare la bontà (performance) di un test diagnostico
disegnare uno schema logico che permetta di valutare la bontà (performance) di un test diagnostico
Nell'unità precedente, abbiamo visto che non esistono test capaci di accertare il reale stato (malato/sano) di un animale in tutte le situazioni e nel 100% dei casi. In altre parole: non esistono test «infallibili». L'esito del test (sia esso positivo, cioè deponga a favore dell'esistenza della malattia, o negativo) deve essere visto come una indicazione di «probabilità».
Inoltre, è facile comprendere come la probabilità di ottenere risultati «veritieri» (cioè aderenti alla realtà) sia soprattutto legata al tipo di test, all'intimo meccanismo del suo funzionamento, e a cosa esso misura . Da ciò deriva che la performance varia da test a test.
Immagina di voler valutare la performance di un test, che chiameremo test X. Per semplicità, supponiamo che questo test fornisca un risultato dicotomico del tipo vero/falso (sano/malato). Il procedimento per valutare la performance del test X prevede che tu abbia a disposizione animali - sia ammalati che sani - dei quali è noto con certezza - o con la massima attendibilità - il reale stato malato/sano. Ciò si può ottenere con metodi diversi a secondo delle circostanze; spesso ci si serve del miglior test disponibile, che viene detto golden test (test aureo). Si assume che i risultati del golden test siano completamente veritieri; in altre parole, si assume che il golden test non sbagli mai.
Il golden test deve essere biologicamente diverso dal test X, ossia deve basarsi su un meccanismo differente.
Procedi quindi a saggiare gli animali sia con il test X che con il golden test, e a inserire i dati ottenuti nelle quattro celle (a, b, c, d) di una Tabella a doppia entrata:
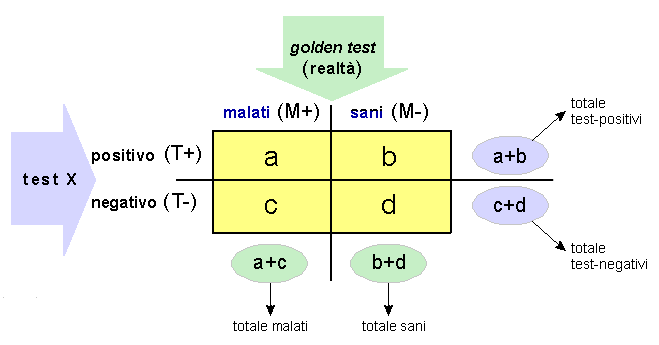
Il significato delle celle è chiaro:
Evidentemente, la performance del test dipende dai valori ottenuti nelle quattro celle, e soprattutto alla proporzione di misclassificazioni (classificazioni errate), rappresentate dai falsi-positivi (cella b) e falsi-negativi (cella c). Con un test infallibile, le misclassificazioni non esistono, quindi b=0 e c=0. Però i test infallibili sono davvero molto rari. I test di comune impiego restituiscono sempre una certa quota di risultati non veritieri e ciò genera una serie di problemi che andremo a considerare in questa Unità e nelle successive.
Tieni presente stiamo considerando una simulazione a scopo didattico. Nella pratica, la popolazione in esame di norma si esamina con un solo test, che ti consente di suddividere gli animali in due gruppi: i «test-positivi» (a+b) e i «test-negativi» (c+d).
Attraverso i quattro valori (a, b, c, d) della Tabella, puoi procedere alla valutazione della performance del test X (sensibilità, specificità valori predittivi ecc.), come vedrai nelle Unità che seguono.
L'individuazione di un golden-test non è sempre facile. Talvolta si può utilizzare un test relativamente semplice e poco costoso. Ad esempio, in un caso di mastite acuta di una bovina, la diagnosi clinica di "mastite da Staphylococcus aureus" viene confermata facilmente attraverso esame colturale del latte (che, in questo caso, rappresenta il golden test). Tuttavia, molto più spesso è necessario ricorrere a golden test lunghi, complicati, costosi o rischiosi per il paziente (es. ![]() laparatomia esplorativa,
laparatomia esplorativa, ![]() biopsia).
biopsia).
Abbiamo detto - e ripetuto - che un test diagnostico fornisce quasi sempre una certa quota di risultati falsi-positivi e falsi-negativi. Di conseguenza, il calcolo della prevalenza di una malattia in una popolazione in base al risultato di un test non fornisce il valore della prevalenza reale, bensì la cosiddetta «prevalenza apparente».
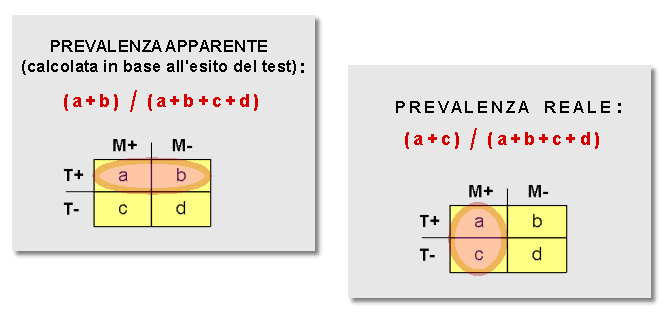
Vedrai in una ![]() prossima Unità come, attraverso il Teorema di Bayes, sia possibile calcolare la prevalenza reale conoscendo la prevalenza apparente e due caratteristiche del test utilizzato: la
prossima Unità come, attraverso il Teorema di Bayes, sia possibile calcolare la prevalenza reale conoscendo la prevalenza apparente e due caratteristiche del test utilizzato: la ![]() sensibilità e la
sensibilità e la ![]() specificità.
specificità.
AFTER HOURS: I test sbagliano... gli stupidi no!
NELLA PROSSIMA UNITÀ:
si spiegano due delle più importanti caratteristiche di un test: la sensibilità e la specificità.